Unicode is fucked. All these bullshit emojis remind me of the 1980s when ASCII was 7 bits but every computer manufacturer (Atari, Commodore, Apple, IBM, TI, etc...) made their own set of characters for the 128 values of a byte beyond ASCII. Of course Unicode is a global standard so your pile-of-poop emoji will still be a pile-of-poop on every device even if the amount of steam is different for some people.
It's beyond me why this is happening. Who decides which bullshit symbols get into the standard anyway?
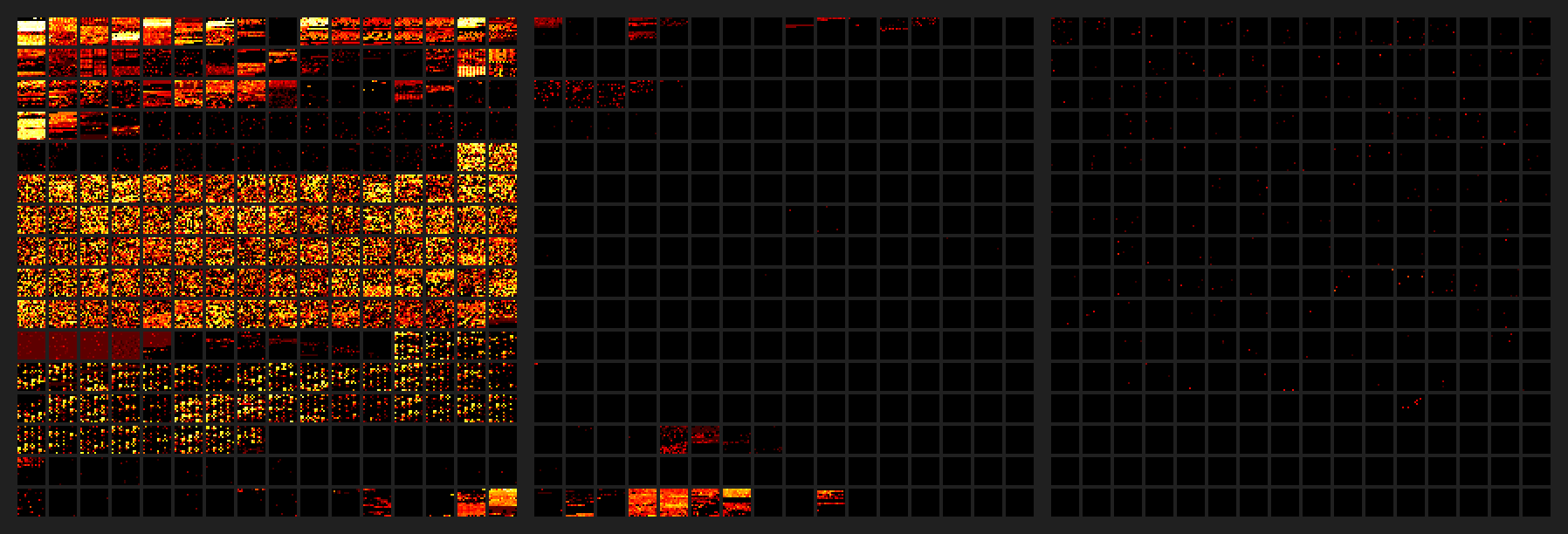
Ah yes, all those bloody emoji taking the place of better worthier characters, those dastardly pictures taking up all of one half of one 16th of one Unicode plane (which has only 16 of those, and only 14 public).
And the gall they have, actually being used and lighting up their section of plane 1 like a christmas tree while the rest of the plane lies in the darkness: http://reedbeta.com/blog/programmers-intro-to-unicode/heatma... what a disgrace, not only existing but being found useful, what has the world come to.
And then of course there's the technical side of things: emoji actually forced western developers — and especially anglo ones — to stop fucking up non-ASCII let alone non-BMP codepoints. I don't think it's a coincidence that MySQL finally added support for astral characters once emoji started getting prominent.
In fact, I have a pet theory that the rash of combining emoji in the latest revisions is in part a vehicle to teach developers to finally stop fucking up text segmentation and stop assuming every codepoint is a grapheme cluster.
Language is inherently complex, there's no way to solve this in any "cleaner" way than what we already came up with. Unfortunately the best way forward is to build up what we already have and cover all the warts with wrapper functions/libraries.
Well, there is one way, we can simplify and standardize format of language. Unfortunately that requires generations of "reeducation", so it's not a viable solution in the short term - but it does seem possible that this is where languages are going in the next few centuries, as globalization, easier travel and more interrelated communities are likely to result in slow, gradual convergence to less languages as many of the current 6000+ languages cease to be used in practice.
I am always surprised when people think that the solution to "dealing with language in programming is complex" is "let's reeducate the world by changing their language" instead of "let's reeducate programmers".
The Love Hotel (U+1F3E9) is rather obvious, maybe the kiss mark (U+1F48B) as well, though the raunchiest ones (in actual use) are a bit more… discreet?: the aubergine (U+1F346) and splashing "sweat" (U+1F4A6).
I'm not sure what use that would be? U+<hex> is a normal way to designate codepoints, and I can't put the actual emoji in the comment as they're stripped on submission.
Unicode is a conflation of two ideas, one good and the other impossible.
The good idea is to have a standard mapping from numbers to little pictures (glyphs, symbols, kanji, ideograms, cuneiform pokings in dried clay, scratches on a rock, whatever.) This is really all ASCII was.
The impossible idea is to encode human languages into bits. This can't be done and will only continue to cause heartache in those who try.
ASCII had English letters but wasn't an encoding for English, although you can and everyone did and does use it for that.
I hate this argument every time I see it because it's invariably used in the wrong place.
Yes, the goal of encoding all human languages into bits is one that's near impossible. Unicode tries, and has broken half-solutions in many places. Lots of heartache everywhere.
This is completely irrelevant to the discussion here. The issue of code points not always mapping to graphemes is only an issue because programmers ignore it. It's a completely solved problem, theoretically speaking. It's necessary to be able to handle many scripts, but it's not something that "breaks" unicode.
> It's a completely solved problem, theoretically speaking.
lol.
Unicode was ambitious for its time, but naive. Today we know better. It "jumped the shark" when the pizza slice showed up and has only been getting stupider since. Eventually it will go the way of XML (yes, I know XML hasn't gone anywhere, shut up) and we will be using some JSON hottness (forgive the labored metaphor please!) that probably consist of a wad of per-language standards and ML/AI/NLP stuff, etc.. blah blah hand-wave.)
Yes, "it jumped the shark when the pizza slice showed up". However, that doesn't imply that it did everything wrong. The notion of multi-codepoint characters is necessary to handle other languages. that is a solved problem, it's just that programmers mess up when dealing with it. Emoji may be a mistake, but the underlying "problems" caused by emoji existed anyway, and they're not really problems, just programmers being stupid.
We had multiple per-language encodings. It sucked.
I don't agree that the notion of multi-codepoint characters is necessary, I don't think it was a good idea at all. I submit [1] as evidence.
Whatever this mess is, it's a whole thing that isn't a byte-stream and it isn't "characters" and it isn't human language. Burn it with fire and let's do something else.
(In reality I am slightly less hard-core, I see some value in Unicode. And I really like Z̨͖̱̟̺̈̒̌̿̔̐̚̕͟͡a̵̭͕͔̬̞̞͚̘͗̀̋̉̋̈̓̏͟͞l̸̛̬̝͎̖̏̊̈́̆̂̓̀̚͢͡ǵ̝̠̰̰̙̘̰̪̏̋̓̉͝o̲̺̹̮̞̓̄̈́͂͑͡ T̜̤͖̖̣̽̓͋̑̕͢͢e̻̝͎̳̖͓̤̎̂͊̀͋̓̽̕͞x̴̛̝͎͔̜͇̾̅͊́̔̀̕t̸̺̥̯͇̯̄͂͆̌̀͞ it is an obvious win.). Even when it doesn't quite work... (I think I'm back to "fuck Unicode" now.)
If anything, their adaptability gives me confidence. They have little power to stop vendors from creating new emojis that are morphologically distinct from existing ones, so they might as well wrangle them into a standard.
There is a Unicode encoding "UTF-32" which has the advantage of being fixed width. This is not popular for the obvious reason that even ascii characters are expanded to 4 bytes. Additionally the windows APIs, among other interfaces, are not equipped to handle 4-byte codepages.
Being fixed width is not an advantage. Code points aren't a very useful unit of text outside of the implementation of algorithms defined by unicode. All of these algorithms generally require iteration anyway. O(1) code point indexing is nearly useless.
It's fixed width with respect to code points, but not with respect to any of the other things mentioned in the linked article. For example, the black heart with emoji variation selector (which makes it render red) is two code points.
> "UTF-32" which has the advantage of being fixed width
It's fixed width for now. It can not hold all the current available code-points, so it will probably have the same fate as UTF-16 (but it will probably take a long time).
There are currently 17 × 65536 code points (U+0000..U+10FFFF) in Unicode. UTF-32 could theoretically encode up to a hypothetical U+FFFFFFFF and still be fixed-width.
Note that, at present, only 4 of the 17 planes have defined characters (Planes 0, 1, 2, and 14), two are reserved for private use (15 and 16), and an additional is unused but is thought to be needed (Plane 3, the TIP for historic Chinese script predecessors). Four planes appear to be sufficient to support every script ever written on Earth, as it's doubtful there are unidentified scripts with an ideographic repertoire as massive as the Unified CJK ideographs database.
We are very unlikely to ever fill up the current space of Unicode, let alone the plausible maximum space permissible by UTF-8, let alone the plausible maximum space permissible by UTF-32.
{kind=link}
It's beyond me why this is happening. Who decides which bullshit symbols get into the standard anyway?